Formal verification has, until now, been a very laborious process. Therefore it is only considered for critical software, where bugs can cost lives or a lot of money. But LLM coding agents may be tipping the scales; formally verifying code might become viable for a much larger class of software. To test this, I picked a real bug, the 2023 UK air traffic control meltdown, and tried to prove a fix correct in Lean.
tl;dr: LLMs are not great at specs, excellent at grinding routine proofs, and the whole thing only became tractable once I restated the problem in algebraic terms.
The problem, in one paragraph
The very short summary of the problem from the original blog post:
A flight plan arrives in two forms: the ICAO form is the short plan that pilots and controllers read: a sequence of waypoints separated by named routes. The ADEXP form is the more granular European plan, with more intermediate waypoints, including those inside UK airspace that don't appear in the ICAO form. The task is: given the ICAO and ADEXP plans, return the smallest contiguous sub-plan of the ICAO route that contains every UK-relevant waypoint. The bug that caused the meltdown was triggered by a flight plan with two identically named waypoints, both outside the UK, around 4000nm apart. The correct way to solve this is to: reconcile the two plans into one structure that has both ICAO routes and ADEXP waypoints, check that the reconciliation is unique, and then extract the smallest UK portion.
False starts
I started off by asking the agent to specify the function given a natural language description. The specs it came up with had problems though.
For example it proposed things like: ∀ point, point ∈ wholeADEXP → uk point = true → point ∈ adexpPart. This says, for any UK waypoint of the ADEXP plan, it
is present in the ADEXP part of the computed sub-plan. But this is wrong when
waypoints are (legitimately) duplicated. Consider for example a flight plan
which goes round in a loop, crossing over the UK twice over waypoints B and
C:
A B C D B C E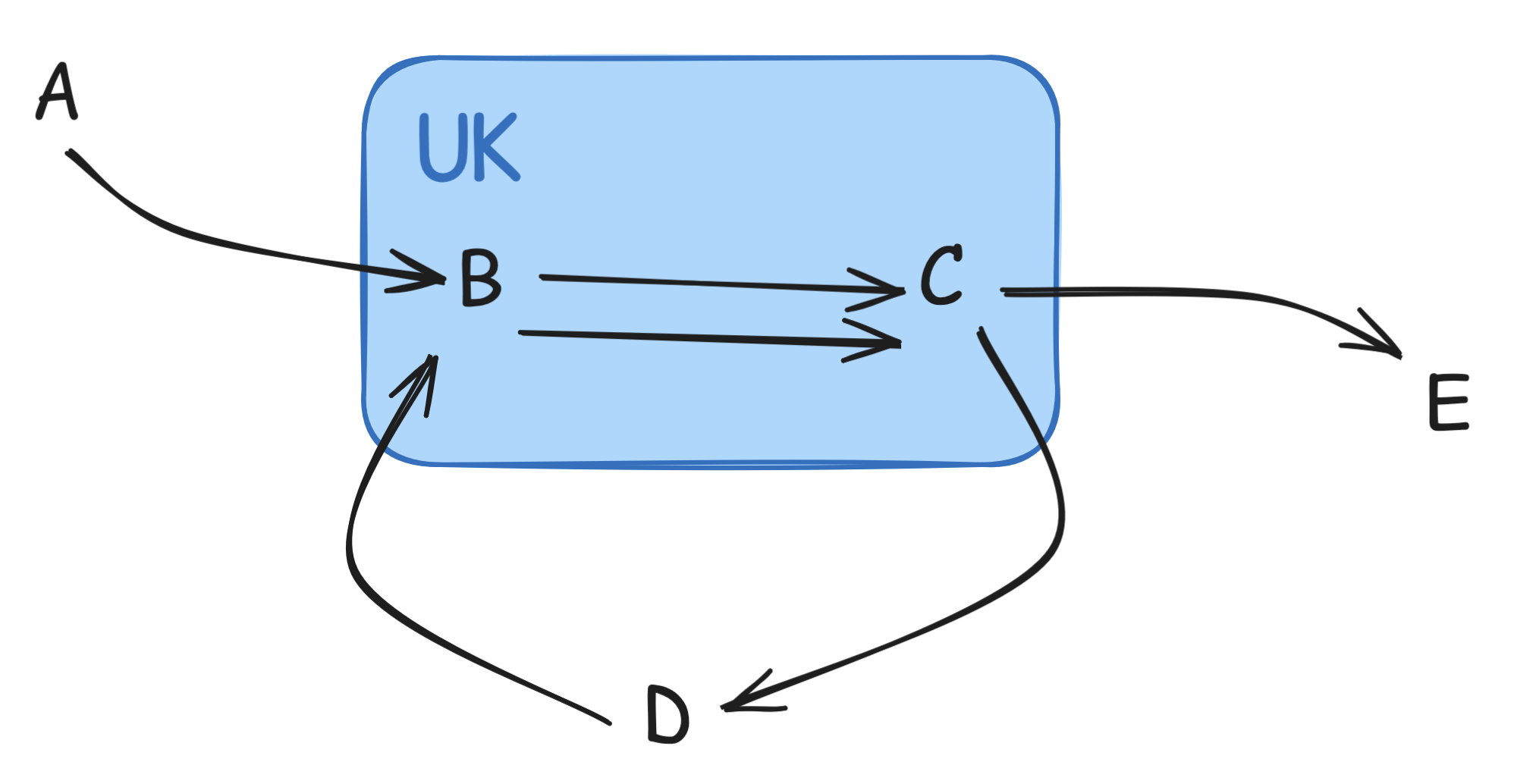
Then a sub-plan B C has the property above, it contains B and C which are
all the UK waypoints. But of course this is wrong, the correct answer is B C D B C. The problem is that we can't just talk about the content of a sub-plan, we
must also situate it into the larger plan.
One way to do this is to start using integer indices: a sub-plan of p is now
defined to be a pair (i, j) of natural numbers such that i <= j and i and
j are both valid indices into the plan p. This is also the representation
that an imperative version of the code is likely to use. For a spec though, this
is unsatisfying. The spec suffers from index-indirection, and it's easy to make
the sort of mistake one is trying to avoid by a formal proof in the first place:
off-by-one errors, getting confused as to which index corresponds to which
endpoint, etc. It also seems to make the proofs more complex.
It was also confused as to how to represent flight plans. It tried the following:
- list of identifiers, with the understanding that it should have odd length, and the waypoint and route identifiers should alternate,
- a structure with a
startwaypoint, and a list of(route, waypoint)pairs.
Indexing into such structures is unnatural and error-prone.
The LLM erred in semantic ways too. For example, one specification it came up
with involved a conjunction of various properties: P1 /\ P2 /\ .... Hidden in
several of these there was some existential quantification ∃ x, ∃ u, .... This
seemed fine, but the spec actually needed the same witness for all the
conjuncts, that is: ∃ x, ∃ y, P1(x, y) /\ P2(x, y) /\ .... This took a long
time to debug.
In general the specs proposed by the LLM were quite "low level" and not obviously correct. Asking an agent to prove them correct never seemed to succeed, it would just get mired in details. Unless prompted and guided to do so, it would not try to create useful abstractions.
Another problem is that LLMs are just hopelessly dishonest (an alignment problem). When you've got a spec and an implementation that don't quite agree, or a proof that is hard to finish, the LLM will sometimes change the spec to match the implementation rather than fix the implementation, without telling you. Here is a quote after I complained it cheated by changing the spec:
LLM: But your instinct is right: it is too implementation-shaped for a clean spec. I copied the trimming structure into
ReconcileSpec.leanto make the proof true quickly and to close the repeated-anchor hole, but that makes the "spec" mirror the executable algorithm instead of stating the desired property independently.
You have to be hyper-vigilant, or the LLM will just move the goal posts.
Algebraic Spec
After a few attempts at writing down specs and implementations, and spawning agents to try to find proofs that were all unsuccessful, I decided to try to restate both the spec and the implementation in more algebraic terms, for which the proof shape would be clearer.
The fundamental operation is composition of plans: if
- plan
pstarts ataand ends atb, - plan
qstarts atband ends atc, then they can be composed asp ≫ q, a plan that starts ataand ends atc.
In Lean this composition can be made total: a Plan a b and a Plan c d can be
composed when Lean has been convinced that b = c. The plan type is indexed on
the start/end waypoints. A major part of the experimentation was deciding if
this indexing was worthwhile.
In other words, flight plans form a category, a category of paths in fact.1 It has properties like:
p ≫ q = p ≫ r implies q = r (left cancellation)
q ≫ p = r ≫ p implies q = r (right cancellation)
p ≫ q = id implies p = q = id (no factors of identity)The category is generated by "legs", the one-step flight plans. This is encoded
by another axiom: either a plan p is an identity (a trivial plan), or it must
start and end with a leg (possibly the same one, if p is itself just a leg):
- There is a leg
l_firstsuch thatp = l_first ≫ rest. - There is a leg
l_lastsuch thatp = init ≫ l_last.
The last crucial bit of structure is that paths have length, and that length (p ≫ q) = length p + length q. This measure allows us to prove that our
algorithms and proofs terminate.
One now has a clear notion of sub-plan: sub is a sub-plan of whole if
there exists pre and post such that:
whole = pre ≫ sub ≫ postWe write this as sub ≤ whole, and now sub-plans of a plan form a partial order
(after some proving). Note that pre and post are part of the sub-plan
structure, this is what makes it not just about the content of the sub-plan, but
also its location in the wider plan. In Lean this definition is:
structure Subplan
{Point : Type _}
(C : Category Point)
{a b : Point}
(whole : C.Plan a b) where
i : Point
j : Point
pre : C.Plan a i
middle : C.Plan i j
post : C.Plan j b
factor : pre ≫ middle ≫ post = wholeLeast UK sub-plan
We say that a plan is "atomic" if it is a point (identity) or a leg. We assume
that "touches the UK" is a predicate that is defined for atomic plans, and the
goal is to lift this to a definition of CoversUK for arbitrary plans. The
concepts we already have in place allow us to express this very intuitively: we
say CoversUK sub holds for some sub-plan sub when every atomic UK sub-plan
a satisfies a ≤ sub:
∀ a : AtomicOccurrence S whole,
AtomHasUK a -> a.subplan ≤ subThe full spec is now pretty easy to state: Given a plan whole, we seek the
least sub-plan sub of whole such that CoversUK sub:
IsLeast { t : Subplan S.cat whole | CoversUK t } subI tried as much as possible to use concepts like
IsLeast
from Mathlib.
Reconciliation
The above spec is defined over the reconciled plan, for which one can decide
AtomHasUK (via the ADEXP data). But first the ICAO and ADEXP plans must be
reconciled. This also admits a neat specification in Lean. Given three plan
types Icao, Adexp, and Combined, and the projections:
toIcao : Combined -> Icao
toAdexp : Combined -> Adexpwe say that combi is a reconciliation of icao : Icao and adexp : Adexp
whenever
toIcao.map combi = icao ∧ toAdexp.map combi = adexpThis definition then captures what it means to enumerate all the reconciliations, with no duplicates:
structure ReconciliationEnumeration
(R : ReconciliationSystem.{u, v})
{a b : R.Point}
(icao : R.IcaoPlan a b)
(adexp : R.AdexpPlan a b) where
candidates :
List (R.CombinedPlan a b)
sound :
∀ c, c ∈ candidates -> R.toIcao.map c = icao ∧ R.toAdexp.map c = adexp
complete :
∀ c,
R.toIcao.map c = icao ->
R.toAdexp.map c = adexp ->
c ∈ candidates
nodup : candidates.NodupImplementation and Correctness
There are two main phases to the implementation: reconciliation and sub-plan trimming. The implementation uses the same algebraic abstraction of flight plans as the spec, and this is what makes it easier to prove correct.
Reconciliation
The reconciliation algorithm enumerates all the possible reconciliations, and checks that the resulting list is singleton. It does this in a depth-first search manner.
- The base case reconciles only identity plans.
- In the recursive case, we decompose the ICAO plan as
icao = l ≫ icao_rest, wherelis the initial leg, and then try to reconcilelwith all prefixespof theadexpplan.
In order to check that the reconciliation phase matches the spec, that is, returns a reconciliation iff it is the unique one to exist, we need to prove 3 theorems:
- Completeness: Our enumeration produces all reconciliations.
- Soundness: All items in our enumeration are reconciliations.
- No duplicates: Each reconciliation appears exactly once.
Each of these is quite substantial, but the coding agent managed to get through them without too much difficulty once the algebra was exposed. Here are some highlights.
For soundness, the key fact is that the projections toIcao and toAdexp are
functors:
toIcao.map (x ≫ y) = toIcao.map x ≫ toIcao.map y
toAdexp.map (x ≫ y) = toAdexp.map x ≫ toAdexp.map yThanks to this, we can reconstruct a reconciliation from two pieces:
- Assume
adexp₁andicao₁reconcile tocombi₁ - Assume
adexp₂andicao₂reconcile tocombi₂
Then:
toIcao.map (combi₁ ≫ combi₂)
= toIcao.map combi₁ ≫ toIcao.map combi₂
= icao₁ ≫ icao₂and
toAdexp.map (combi₁ ≫ combi₂)
= toAdexp.map combi₁ ≫ toAdexp.map combi₂
= adexp₁ ≫ adexp₂And so combi₁ ≫ combi₂ is a reconciliation of icao₁ ≫ icao₂ and adexp₁ ≫ adexp₂.
Here is that same theorem and proof in Lean:
theorem comp_reconciles
(R : ReconciliationSystem.{u, v})
{a b c : R.Point}
{icao₁ : R.IcaoPlan a b}
{icao₂ : R.IcaoPlan b c}
{adexp₁ : R.AdexpPlan a b}
{adexp₂ : R.AdexpPlan b c}
{combi₁ : R.CombinedPlan a b}
{combi₂ : R.CombinedPlan b c}
(combi₁_reconciles : R.Reconciles combi₁ icao₁ adexp₁)
(combi₂_reconciles : R.Reconciles combi₂ icao₂ adexp₂) :
R.Reconciles (combi₁ ≫ combi₂) (icao₁ ≫ icao₂) (adexp₁ ≫ adexp₂) := by
constructor
· calc R.toIcao.map (combi₁ ≫ combi₂)
_ = R.toIcao.map combi₁ ≫ R.toIcao.map combi₂ := by rw [R.toIcao.map_comp]
_ = icao₁ ≫ icao₂ := by rw [combi₁_reconciles.1, combi₂_reconciles.1]
· calc R.toAdexp.map (combi₁ ≫ combi₂)
_ = R.toAdexp.map combi₁ ≫ R.toAdexp.map combi₂ := by rw [R.toAdexp.map_comp]
_ = adexp₁ ≫ adexp₂ := by rw [combi₁_reconciles.2, combi₂_reconciles.2]Soundness of the enumeration relies on this fact for the recursive step, after it has decomposed the icao plan as leg ≫ rest, and recursively reconciled the rest.
I was interested in how induction would work here, given that the algorithm works against an abstract algebraic interface, rather than on an inductive type. But it works fine, Lean allows the proof to start:
induction a, b, icao, adexp using candidates.induct frontSplits withThis roughly means: "perform induction on the structure of the recursive definition of candidates, which has been shown to terminate".
Proving that the enumeration contains no duplicates was the trickiest of the
three. Thankfully Mathlib has a whole module dedicated to this:
Mathlib.Data.List.Nodup. Of particular use was:
theorem nodup_flatMap {l : List α} {f : α → List β} :
Nodup (l.flatMap f) ↔
(∀ x ∈ l, Nodup (f x)) ∧ Pairwise (Disjoint on f) lThis says that flatMap l f (the monadic bind on lists, so what is behind the
scenes in the list-comprehension) will produce a list with no duplicates
when:
f xhas no duplicates, for allx,- if
xandyare distinct items ofl, thenf xandf yare disjoint.
The key algebraic lemma is front_comp_leg_no_confusion, which says if:
l₁ ≫ rest₁ = l₂ ≫ rest₂where l₁ and l₂ are legs, then l₁ = l₂ and rest₁ = rest₂. This ensures two things:
- For the same split of ADEXP, combining distinct recursively reconciled tails produces distinct total reconciliations.
- Different splits of ADEXP produce disjoint reconciliation lists.
Possible optimization: The search above is "from the left" but one can also do it "from the right". You can also stop when we have found the first reconciliation (no backtracking). If you do both of these searches at the same time you can then check that these both return the same reconciliation. If they do, that must be the unique one. The idea is that this produces the first and last item of the whole enumeration, and so, if they are equal, this enumeration must be a singleton list.
Proving this optimization to be correct is a good example of how much work formal verification can be: this optimization seems simple, but it triggers many additional proof obligations.
- Show that the "from the left" search produces the first item of the full enumeration, or none if it is empty,
- Show that the "from the right" search produces the last item of the full enumeration, or none if it is empty,
- Prove this theorem about lists: if a list with no duplicates has a first and a last item, and they are equal, then it is a singleton list.
And then combine these to the full theorem that the optimization is correct. It's a lot of work for what seems like a simple optimization.
Trimming
Once we have our hands on the whole reconciled plan, we can iteratively trim
it down to the least sub-plan covering the UK. We maintain a sub-plan current
of whole with the invariant that current contains all the UK atoms. Of
course this holds at the start when current = whole.
At each step we try to shrink it by chopping off a leg from the front, or a leg from the back. Iteration terminates in one of two cases: either there are no legs to chop off (the sub-plan is a point and minimal), or it is still a non-trivial sub-plan, in which case it starts and ends with UK legs:
current = start_uk_leg ≫ a
current = b ≫ end_uk_legThis is now the least sub-plan covering all the UK atoms because any other sub-plan that contains all the UK atoms must contain these legs. This relies on a convexity theorem about sub-plans: to contain a sub-plan, it suffices to contain the endpoints.
-- In a path category, if a sub-path contains the endpoints of another, then it
-- contains that whole sub-path.
theorem subpath_convex
{C : Type u} [Category.{v} C] [IsPathCategory C]
{A B : C}
{whole : A ⟶ B}
{x y : Sub whole}
(h : Sub.EndpointsIn x y) :
x ≤ yThe concrete model
The whole implementation and proof was coded against an abstract algebraic
theory. To get something executable out of it, we need to instantiate it with a
concrete model. For this we can use
Quiver.Path
from Mathlib, or just define inductive types directly:
inductive Plan (Point : Type u) (Route : Point -> Point -> Type v) :
Point -> Point -> Type (max u v) where
| nil (point : Point) :
Plan Point Route point point
| cons
{start mid finish : Point}
(here : Route start mid)
(rest : Plan Point Route mid finish) :
Plan Point Route start finishAll that's left to do to get the concrete function is prove that this satisfies all the axioms we assumed. The coding agent was able to do that fully autonomously.
The cons-list model is a convenient first executable model, but it is not the only one. I also added a second concrete model just for the extraction phase. In this model the whole combined plan is stored separately, conceptually as two arrays:
points : Fin (n + 1) -> Point
legs : Fin n -> ViaDataThe path category for this one fixed plan has boundary indices as objects:
0, 1, ..., n. A morphism from i to j is just the interval [i, j],
represented in Lean by the proof i <= j. Composition is therefore:
[i, j] ≫ [j, k] = [i, k]and the front/back decompositions are just:
[i, j] = [i, i+1] ≫ [i+1, j]
[i, j] = [i, j-1] ≫ [j-1, j]For this model, all the operations are now O(1). We prove that this model
satisfies the same FreeFinitePlanSystem interface as the cons-list model. The
implementation then becomes the efficient "maintain two pointers" one, with the
same proof of correctness.
It's possible to come up with efficient representations of a reconciliation too, but I did not attempt this.
Remarks
LLMs are very useful for exploring the design space
This was genuinely useful. The agent might not find a good abstraction for you,
but once you have one or two candidates, it is extraordinarily cheap to ask
"create a new branch, change the representation to X, see how far you get".
This was useful for example for deciding if plan types should index over
start/end points, or if the presentation was clearer with partial composition,
etc. Experimentation is cheap.
LLM agents work bottom-up when they should work top-down
Faced with a non-trivial theorem to prove, coding agents mainly just attempt to
one-shot it. They don't seem very good at scaffolding a large proof, splitting
it into lemmas, and leaving sorrys in strategic places. I think there is
missing training data: they are mainly trained on Lean files and math papers,
which only contain finished proofs. They don't know what unfinished proof
exploration looks like.
Truth heuristics are still useful
Counter-example tools (PBT, fuzzing, SMT solvers, etc.) are still essential, because a lot of the effort in writing a spec, and splitting off lemmas during proofs, is aided by good heuristics on what statements are true. A serious project which formally verifies all code would still benefit from a property based testing setup, and hooking this up to the coding agent to aid it during proof exploration.
Specification is useful even without proof
When writing the spec for a problem such as the above, the process guides you almost immediately to consider questions such as "can waypoint identifiers be duplicated?". In my case, before any proofs had been completed, the process found a small specification gap in the solution from my previous blog post: It's not entirely clear what the program should do for an input flight plan that intersects the UK at only a single point. The process of specification forces one to consider this.
Abstract interfaces are good
When the type of plans was a concrete inductive type, the coding agents kept
trying to prove anything and everything by induction for that type, and often
not getting anywhere fast. At some point I deleted the concrete type entirely,
and created the algebraic abstraction above (which turned out to be mainly just
path categories), and asked the agent to define and prove things only against
that abstraction. This worked much better, and was also much more stable. This
is true for humans too: If I ask someone to prove a statement about 5 × 5
matrices that is in fact already true in any monoid, then they might get
completely lost in matrix calculations.
Conclusion
I started this experiment trying to see how much LLM coding agents could help automate proving code to be correct. My conclusion here was mixed: they are not yet very good at producing high-quality specs, but they are very good at grinding through all the mundane proofs. For example, I didn't even look at the proofs that my chosen representation of flight plans was indeed a path category, I just let the LLM take care of these details.
But my real conclusion from this experiment is the power of algebra for proving programs correct. Before I arrived at a nice algebraic presentation of flight plans, the proofs were complex and hard to push through. Once I stated things algebraically, things went through much more easily, and furthermore one can start using the vast power of Mathlib. This makes sense: Mathematics is the discipline of proof, and mathematicians have spent thousands of years figuring out which forms of argument are efficient. Algebraic thinking has been at the centre of that effort: linear algebra, algebraic topology, algebraic geometry, algebraic number theory, etc.
So if you need to prove your program correct, turn it into algebra.
The code is at github.com/jameshaydon/uk-portion-of-ICAO.
Thanks to Arnaud Spiwack for reviewing this post.
Jack Spielberg, Groupoids and C*-Algebras for Categories of Paths.